Double Your Revenue With These 5 Tips about Deepseek
페이지 정보
작성자 Janelle Barring… 작성일25-02-17 15:11 조회4회 댓글0건관련링크
본문
 Mistral’s announcement weblog submit shared some fascinating information on the performance of Codestral benchmarked against three much larger models: CodeLlama 70B, DeepSeek Coder 33B, and Llama three 70B. They examined it utilizing HumanEval move@1, MBPP sanitized cross@1, CruxEval, RepoBench EM, and the Spider benchmark. DeepSeek R1 and V3 models might be downloaded and run on private computer systems for users who prioritise data privateness or want an area installation. So you'll be able to have completely different incentives. A lot of people, nervous about this example, have taken to morbid humor. It's a decently massive (685 billion parameters) mannequin and apparently outperforms Claude 3.5 Sonnet and GPT-4o on a number of benchmarks. I can't easily find evaluations of present-technology value-optimized models like 4o and Sonnet on this. The paper says that they tried applying it to smaller models and it did not work nearly as effectively, so "base models have been dangerous then" is a plausible explanation, but it is clearly not true - GPT-4-base might be a typically better (if costlier) model than 4o, which o1 is predicated on (could be distillation from a secret bigger one though); and LLaMA-3.1-405B used a somewhat related postttraining course of and is about nearly as good a base model, however isn't aggressive with o1 or R1.
Mistral’s announcement weblog submit shared some fascinating information on the performance of Codestral benchmarked against three much larger models: CodeLlama 70B, DeepSeek Coder 33B, and Llama three 70B. They examined it utilizing HumanEval move@1, MBPP sanitized cross@1, CruxEval, RepoBench EM, and the Spider benchmark. DeepSeek R1 and V3 models might be downloaded and run on private computer systems for users who prioritise data privateness or want an area installation. So you'll be able to have completely different incentives. A lot of people, nervous about this example, have taken to morbid humor. It's a decently massive (685 billion parameters) mannequin and apparently outperforms Claude 3.5 Sonnet and GPT-4o on a number of benchmarks. I can't easily find evaluations of present-technology value-optimized models like 4o and Sonnet on this. The paper says that they tried applying it to smaller models and it did not work nearly as effectively, so "base models have been dangerous then" is a plausible explanation, but it is clearly not true - GPT-4-base might be a typically better (if costlier) model than 4o, which o1 is predicated on (could be distillation from a secret bigger one though); and LLaMA-3.1-405B used a somewhat related postttraining course of and is about nearly as good a base model, however isn't aggressive with o1 or R1.
The process is straightforward-sounding however filled with pitfalls DeepSeek don't mention? Is this simply because GPT-4 benefits heaps from posttraining whereas Free DeepSeek Ai Chat evaluated their base mannequin, or is the model nonetheless worse in some hard-to-check method? Except for, I think, older variations of Udio, they all sound constantly off in some way I don't know enough music idea to explain, significantly in metal vocals and/or complicated instrumentals. Why do all three of the moderately okay AI music tools (Udio, Suno, Riffusion) have pretty related artifacts? They avoid tensor parallelism (interconnect-heavy) by carefully compacting all the pieces so it matches on fewer GPUs, designed their very own optimized pipeline parallelism, wrote their own PTX (roughly, Nvidia GPU meeting) for low-overhead communication so they can overlap it better, fix some precision points with FP8 in software program, casually implement a new FP12 format to retailer activations extra compactly and have a bit suggesting hardware design changes they'd like made. And you can even pay-as-you-go at an unbeatable value.
My favorite part up to now is that this exercise - you may uniquely (up to a dimensionless constant) identify this formulation just from some ideas about what it should include and a small linear algebra problem! The sudden emergence of a small Chinese startup capable of rivalling Silicon Valley’s top gamers has challenged assumptions about US dominance in AI and raised fears that the sky-high market valuations of firms resembling Nvidia and Meta could also be detached from reality. Abraham, the previous analysis director at Stability AI, said perceptions could even be skewed by the fact that, unlike DeepSeek, corporations corresponding to OpenAI haven't made their most advanced models freely obtainable to the general public. The ban is supposed to stop Chinese firms from training top-tier LLMs. Companies like the Silicon Valley chipmaker Nvidia initially designed these chips to render graphics for computer video games. AI chatbots are computer programmes which simulate human-model conversation with a user. Organizations may need to reevaluate their partnerships with proprietary AI suppliers, contemplating whether or not the high costs related to these services are justified when open-source alternate options can deliver comparable, if not superior, results. Interested builders can join on the DeepSeek Open Platform, create API keys, and comply with the on-display instructions and documentation to combine their desired API.
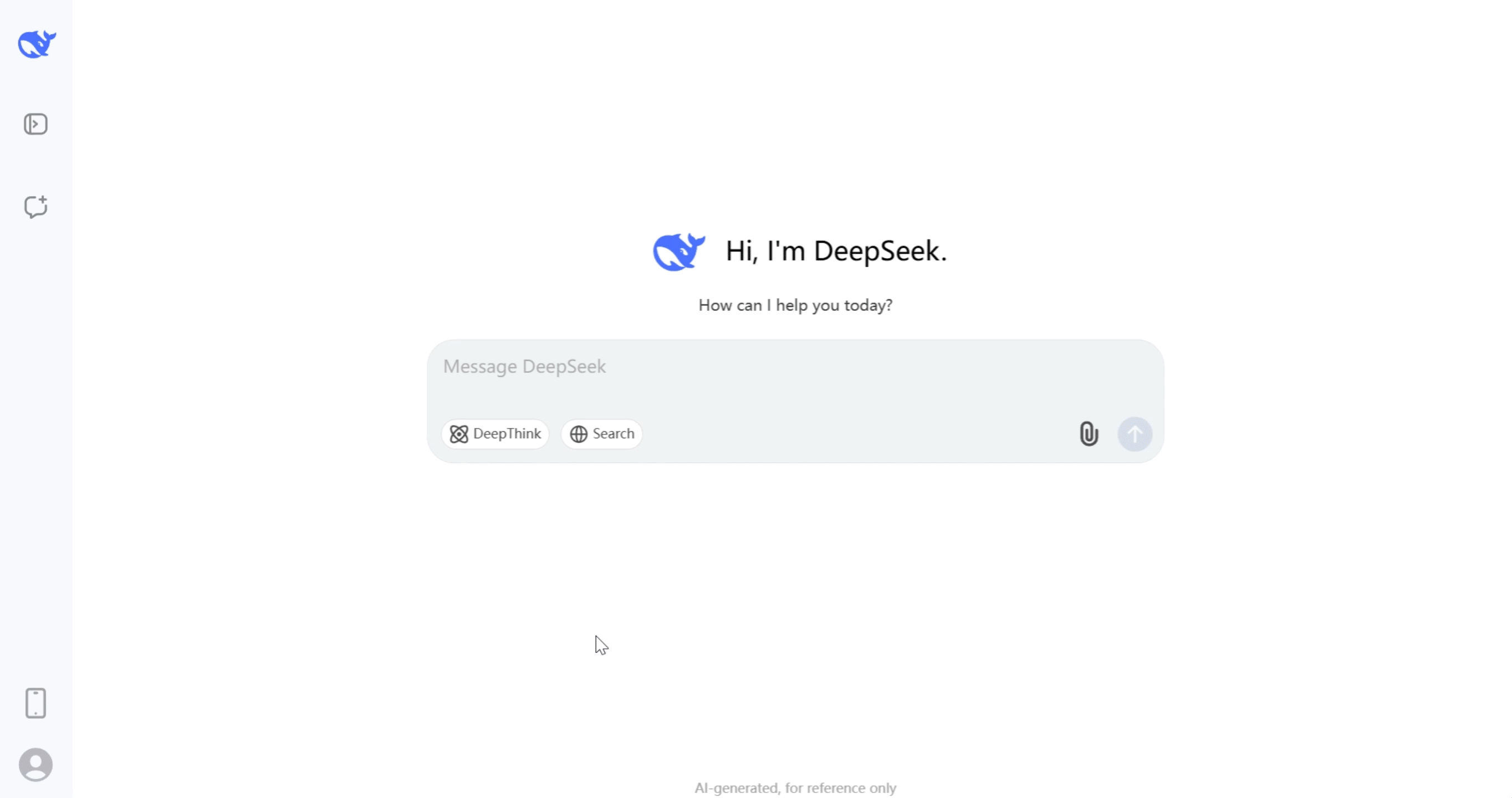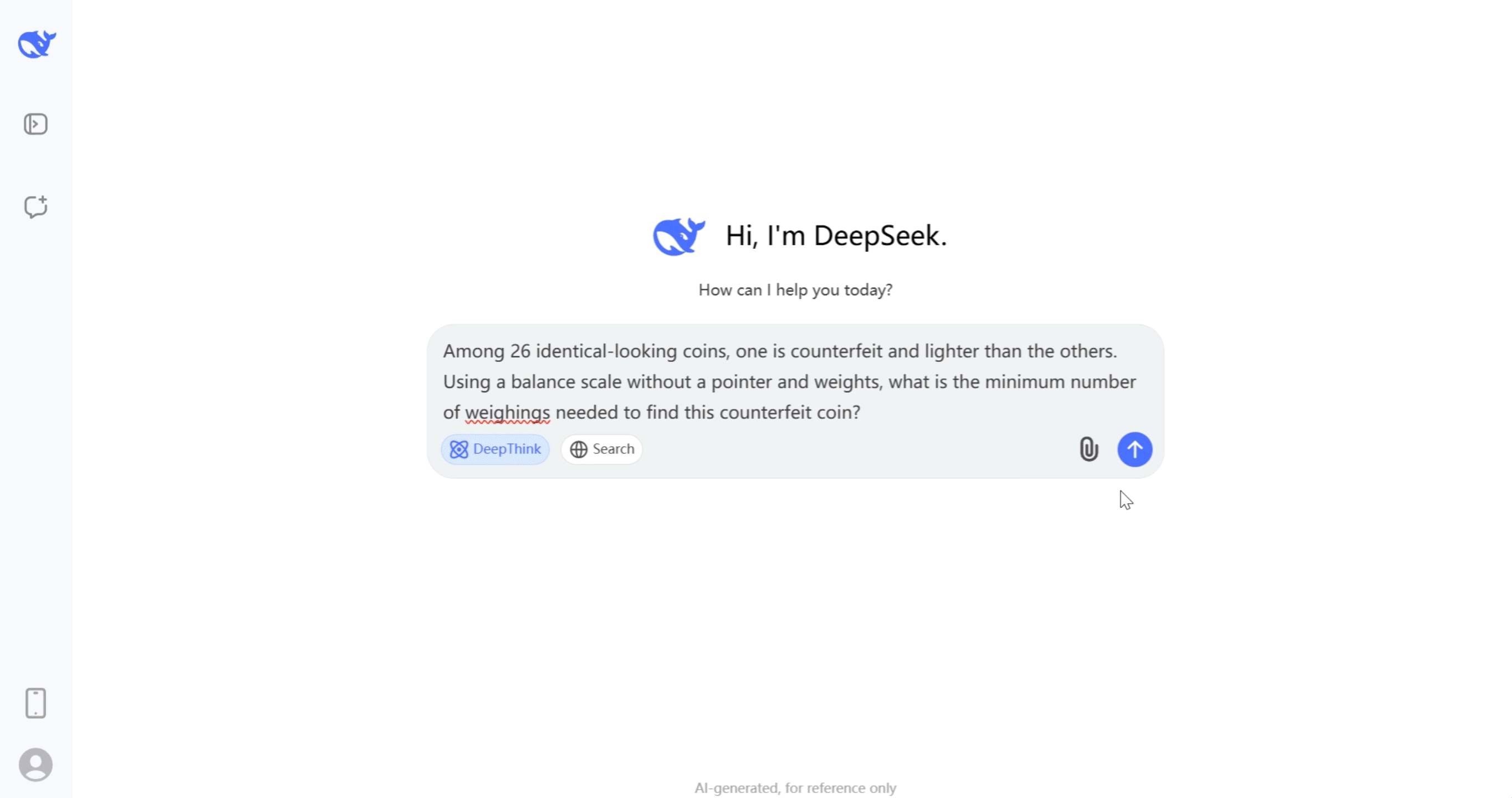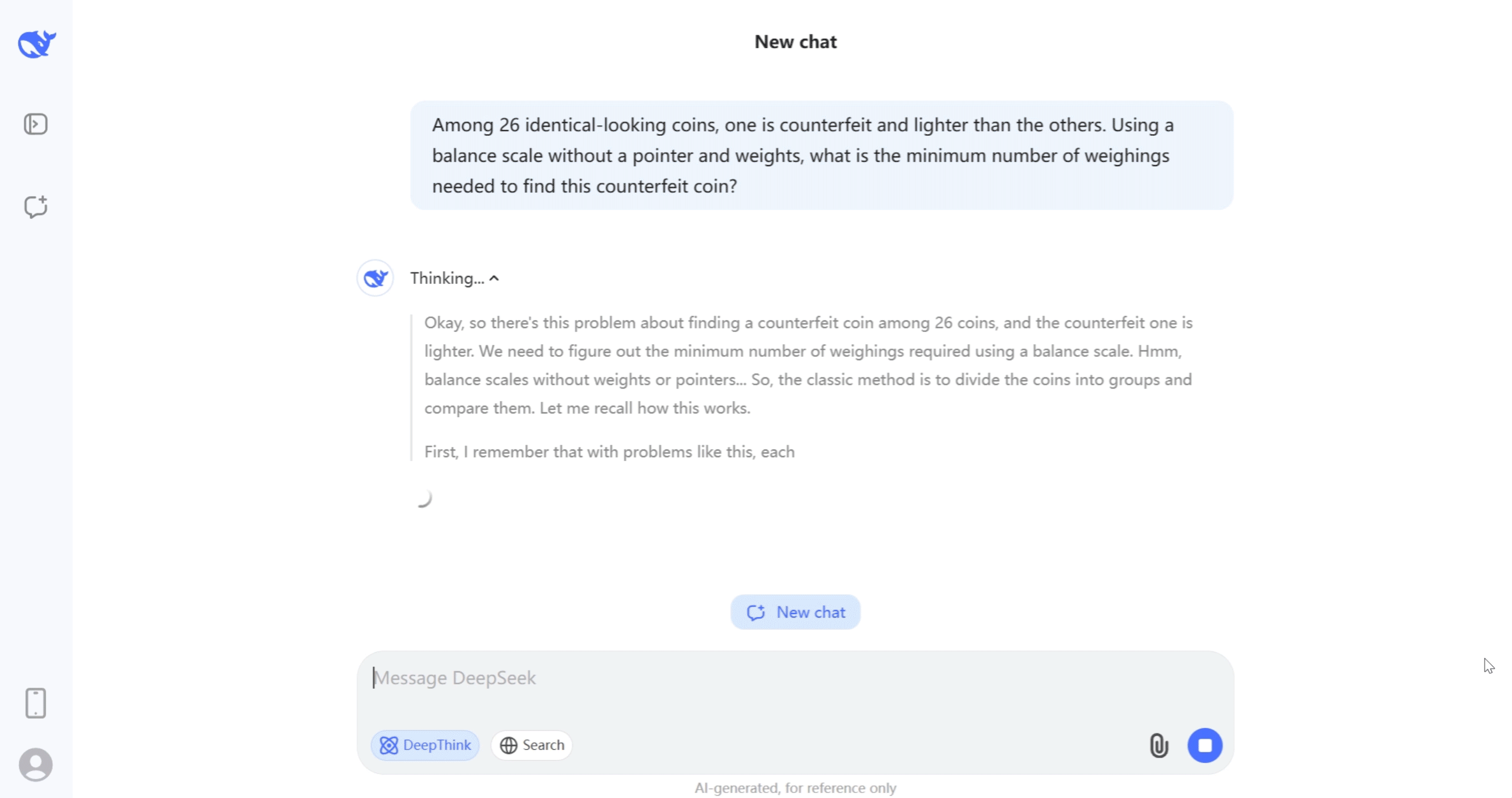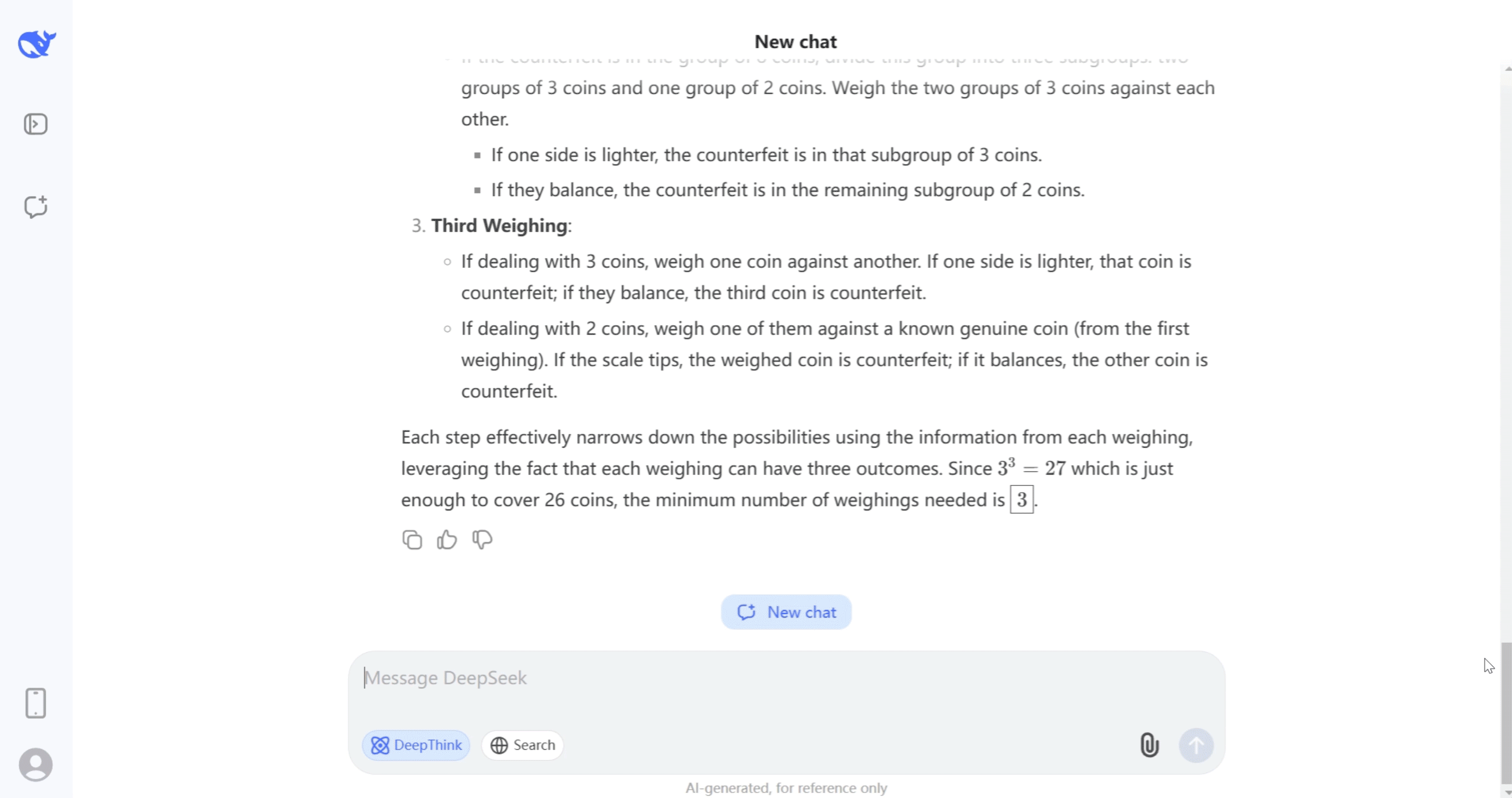 3. Check against present literature using Semantic Scholar API and internet access. Please make certain to make use of the newest model of the Tabnine plugin in your IDE to get access to the Codestral mannequin. Based on Mistral’s efficiency benchmarking, you may anticipate Codestral to significantly outperform the other tested fashions in Python, Bash, Java, and PHP, with on-par performance on the opposite languages examined. In 2023 the office set limits on the use of ChatGPT, telling workplaces they'll only use the paid version of the OpenAI chatbot for sure duties. OpenAI GPT-4o, GPT-4 Turbo, and GPT-3.5 Turbo: These are the industry’s hottest LLMs, proven to deliver the best ranges of efficiency for teams willing to share their knowledge externally. Mistral: This model was developed by Tabnine to deliver the best class of efficiency throughout the broadest variety of languages while nonetheless sustaining complete privateness over your data. Various web tasks I have put together over a few years. The following step is of course "we'd like to construct gods and put them in all the pieces".
3. Check against present literature using Semantic Scholar API and internet access. Please make certain to make use of the newest model of the Tabnine plugin in your IDE to get access to the Codestral mannequin. Based on Mistral’s efficiency benchmarking, you may anticipate Codestral to significantly outperform the other tested fashions in Python, Bash, Java, and PHP, with on-par performance on the opposite languages examined. In 2023 the office set limits on the use of ChatGPT, telling workplaces they'll only use the paid version of the OpenAI chatbot for sure duties. OpenAI GPT-4o, GPT-4 Turbo, and GPT-3.5 Turbo: These are the industry’s hottest LLMs, proven to deliver the best ranges of efficiency for teams willing to share their knowledge externally. Mistral: This model was developed by Tabnine to deliver the best class of efficiency throughout the broadest variety of languages while nonetheless sustaining complete privateness over your data. Various web tasks I have put together over a few years. The following step is of course "we'd like to construct gods and put them in all the pieces".
댓글목록
등록된 댓글이 없습니다.