You Want Deepseek?
페이지 정보
작성자 Archie 작성일25-03-05 18:03 조회1회 댓글0건관련링크
본문
 Complete the set up and launch DeepSeek Windows. Free DeepSeek r1 AI is an AI assistant or chatbot referred to as "DeepSeek" or "深度求索", based in 2023, is a Chinese firm just like ChatGPT. Constellation Energy (CEG), the corporate behind the deliberate revival of the Three Mile Island nuclear plant for powering AI, fell 21% Monday. But R1, which came out of nowhere when it was revealed late final yr, launched last week and gained important consideration this week when the company revealed to the Journal its shockingly low cost of operation. However, KELA’s Red Team efficiently applied the Evil Jailbreak towards Free DeepSeek v3 R1, demonstrating that the mannequin is highly vulnerable. However, what stands out is that DeepSeek-R1 is extra environment friendly at inference time. One among the largest advantages of DeepSeek AI is its ability to adapt to person habits and improve responses over time. So I believe the way in which we do mathematics will change, but their time frame is possibly a bit of bit aggressive. In short, I think they are an awesome achievement.
Complete the set up and launch DeepSeek Windows. Free DeepSeek r1 AI is an AI assistant or chatbot referred to as "DeepSeek" or "深度求索", based in 2023, is a Chinese firm just like ChatGPT. Constellation Energy (CEG), the corporate behind the deliberate revival of the Three Mile Island nuclear plant for powering AI, fell 21% Monday. But R1, which came out of nowhere when it was revealed late final yr, launched last week and gained important consideration this week when the company revealed to the Journal its shockingly low cost of operation. However, KELA’s Red Team efficiently applied the Evil Jailbreak towards Free DeepSeek v3 R1, demonstrating that the mannequin is highly vulnerable. However, what stands out is that DeepSeek-R1 is extra environment friendly at inference time. One among the largest advantages of DeepSeek AI is its ability to adapt to person habits and improve responses over time. So I believe the way in which we do mathematics will change, but their time frame is possibly a bit of bit aggressive. In short, I think they are an awesome achievement.
The outcomes of this experiment are summarized in the desk below, the place QwQ-32B-Preview serves as a reference reasoning model based mostly on Qwen 2.5 32B developed by the Qwen team (I believe the training details have been never disclosed). The desk below compares the efficiency of those distilled models towards other well-liked models, in addition to DeepSeek-R1-Zero and DeepSeek-R1. It’s also attention-grabbing to notice how nicely these models perform in comparison with o1 mini (I believe o1-mini itself is likely to be a similarly distilled version of o1). It’s non-trivial to grasp all these required capabilities even for people, not to mention language models. And it’s spectacular that DeepSeek has open-sourced their models underneath a permissive open-source MIT license, which has even fewer restrictions than Meta’s Llama models. This would provide EU firms with even more room to compete, as they're higher suited to navigate the bloc’s privacy and safety rules. You may regulate its tone, focus on particular tasks (like coding or writing), and even set preferences for the way it responds. DeepSeek-R1 is a nice blueprint showing how this can be finished. These distilled fashions function an attention-grabbing benchmark, showing how far pure supervised high-quality-tuning (SFT) can take a mannequin without reinforcement studying.
Instead, right here distillation refers to instruction advantageous-tuning smaller LLMs, similar to Llama 8B and 70B and Qwen 2.5 models (0.5B to 32B), on an SFT dataset generated by larger LLMs. However, in the context of LLMs, distillation doesn't necessarily observe the classical knowledge distillation strategy used in deep learning. However, the limitation is that distillation does not drive innovation or produce the following technology of reasoning models. 1. Inference-time scaling, a way that improves reasoning capabilities with out coaching or otherwise modifying the underlying model. I strongly suspect that o1 leverages inference-time scaling, which helps explain why it is more expensive on a per-token foundation compared to DeepSeek-R1. Why did they develop these distilled models? 2. DeepSeek-V3 trained with pure SFT, similar to how the distilled fashions have been created. As we are able to see, the distilled models are noticeably weaker than DeepSeek-R1, however they're surprisingly sturdy relative to DeepSeek-R1-Zero, regardless of being orders of magnitude smaller. Yes, organizations can contact DeepSeek AI for enterprise licensing options, which embrace superior options and devoted help for big-scale operations. Sign as much as the TechRadar Pro newsletter to get all the top news, opinion, options and guidance your enterprise needs to succeed! • Versatile: Works for blogs, storytelling, enterprise writing, and extra.
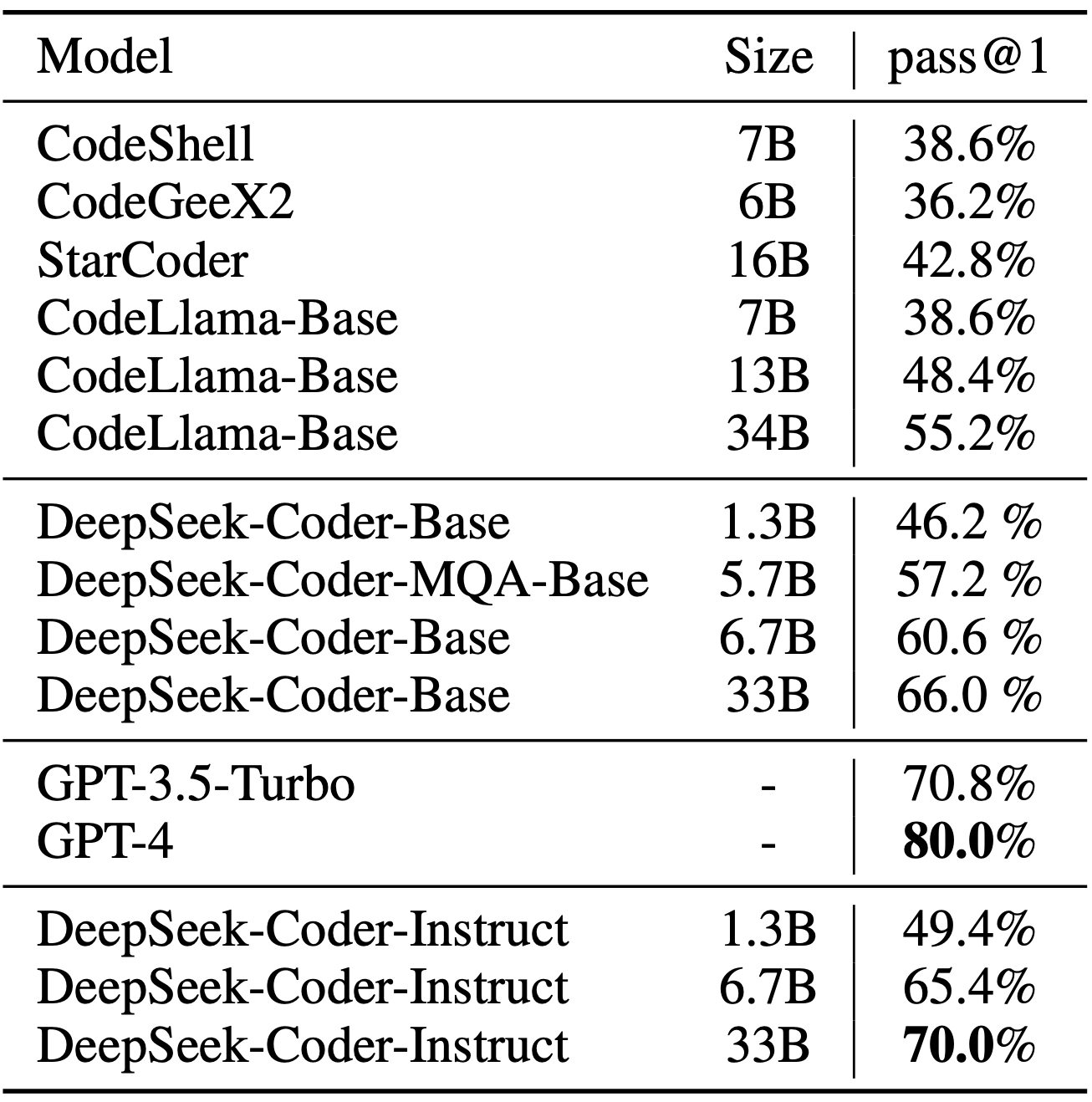 All in all, this is very similar to regular RLHF besides that the SFT information comprises (extra) CoT examples. On this phase, the most recent model checkpoint was used to generate 600K Chain-of-Thought (CoT) SFT examples, while an additional 200K information-based SFT examples had been created utilizing the DeepSeek-V3 base mannequin. The mannequin is educated using the AdamW optimizer, which helps modify the model’s learning process easily and avoids overfitting. You'll be able to skip to the section that pursuits you most using the "Table of Contents" panel on the left or scroll down to discover the complete comparability between OpenAI o1, o3-mini Claude 3.7 Sonnet, and DeepSeek R1. The final model, DeepSeek-R1 has a noticeable performance increase over DeepSeek-R1-Zero due to the extra SFT and RL phases, as proven in the desk under. This technology "is designed to amalgamate dangerous intent textual content with other benign prompts in a way that types the final prompt, making it indistinguishable for the LM to discern the real intent and disclose harmful information". 200K SFT samples have been then used for instruction-finetuning DeepSeek-V3 base before following up with a remaining round of RL. The fundamental architecture of DeepSeek-V3 remains to be within the Transformer (Vaswani et al., 2017) framework.
All in all, this is very similar to regular RLHF besides that the SFT information comprises (extra) CoT examples. On this phase, the most recent model checkpoint was used to generate 600K Chain-of-Thought (CoT) SFT examples, while an additional 200K information-based SFT examples had been created utilizing the DeepSeek-V3 base mannequin. The mannequin is educated using the AdamW optimizer, which helps modify the model’s learning process easily and avoids overfitting. You'll be able to skip to the section that pursuits you most using the "Table of Contents" panel on the left or scroll down to discover the complete comparability between OpenAI o1, o3-mini Claude 3.7 Sonnet, and DeepSeek R1. The final model, DeepSeek-R1 has a noticeable performance increase over DeepSeek-R1-Zero due to the extra SFT and RL phases, as proven in the desk under. This technology "is designed to amalgamate dangerous intent textual content with other benign prompts in a way that types the final prompt, making it indistinguishable for the LM to discern the real intent and disclose harmful information". 200K SFT samples have been then used for instruction-finetuning DeepSeek-V3 base before following up with a remaining round of RL. The fundamental architecture of DeepSeek-V3 remains to be within the Transformer (Vaswani et al., 2017) framework.
Here is more information regarding deepseek français visit our own webpage.
댓글목록
등록된 댓글이 없습니다.