Run DeepSeek-R1 Locally at no Cost in Just Three Minutes!
페이지 정보
작성자 Maricruz 작성일25-01-31 08:53 조회255회 댓글0건관련링크
본문
 In only two months, DeepSeek came up with one thing new and attention-grabbing. Model measurement and structure: The DeepSeek-Coder-V2 model is available in two main sizes: a smaller version with sixteen B parameters and a bigger one with 236 B parameters. Training data: Compared to the unique DeepSeek-Coder, DeepSeek-Coder-V2 expanded the coaching knowledge significantly by including an additional 6 trillion tokens, increasing the total to 10.2 trillion tokens. High throughput: DeepSeek V2 achieves a throughput that's 5.76 instances increased than DeepSeek 67B. So it’s able to producing textual content at over 50,000 tokens per second on commonplace hardware. DeepSeek-Coder-V2, costing 20-50x occasions lower than different fashions, represents a big upgrade over the original DeepSeek-Coder, with extra extensive training knowledge, larger and extra efficient fashions, enhanced context handling, and advanced strategies like Fill-In-The-Middle and Reinforcement Learning. Large language models (LLM) have shown spectacular capabilities in mathematical reasoning, however their software in formal theorem proving has been limited by the lack of coaching data. The freshest model, released by DeepSeek in August 2024, is an optimized version of their open-supply model for theorem proving in Lean 4, DeepSeek-Prover-V1.5. The excessive-quality examples were then passed to the DeepSeek-Prover mannequin, which tried to generate proofs for them.
In only two months, DeepSeek came up with one thing new and attention-grabbing. Model measurement and structure: The DeepSeek-Coder-V2 model is available in two main sizes: a smaller version with sixteen B parameters and a bigger one with 236 B parameters. Training data: Compared to the unique DeepSeek-Coder, DeepSeek-Coder-V2 expanded the coaching knowledge significantly by including an additional 6 trillion tokens, increasing the total to 10.2 trillion tokens. High throughput: DeepSeek V2 achieves a throughput that's 5.76 instances increased than DeepSeek 67B. So it’s able to producing textual content at over 50,000 tokens per second on commonplace hardware. DeepSeek-Coder-V2, costing 20-50x occasions lower than different fashions, represents a big upgrade over the original DeepSeek-Coder, with extra extensive training knowledge, larger and extra efficient fashions, enhanced context handling, and advanced strategies like Fill-In-The-Middle and Reinforcement Learning. Large language models (LLM) have shown spectacular capabilities in mathematical reasoning, however their software in formal theorem proving has been limited by the lack of coaching data. The freshest model, released by DeepSeek in August 2024, is an optimized version of their open-supply model for theorem proving in Lean 4, DeepSeek-Prover-V1.5. The excessive-quality examples were then passed to the DeepSeek-Prover mannequin, which tried to generate proofs for them.
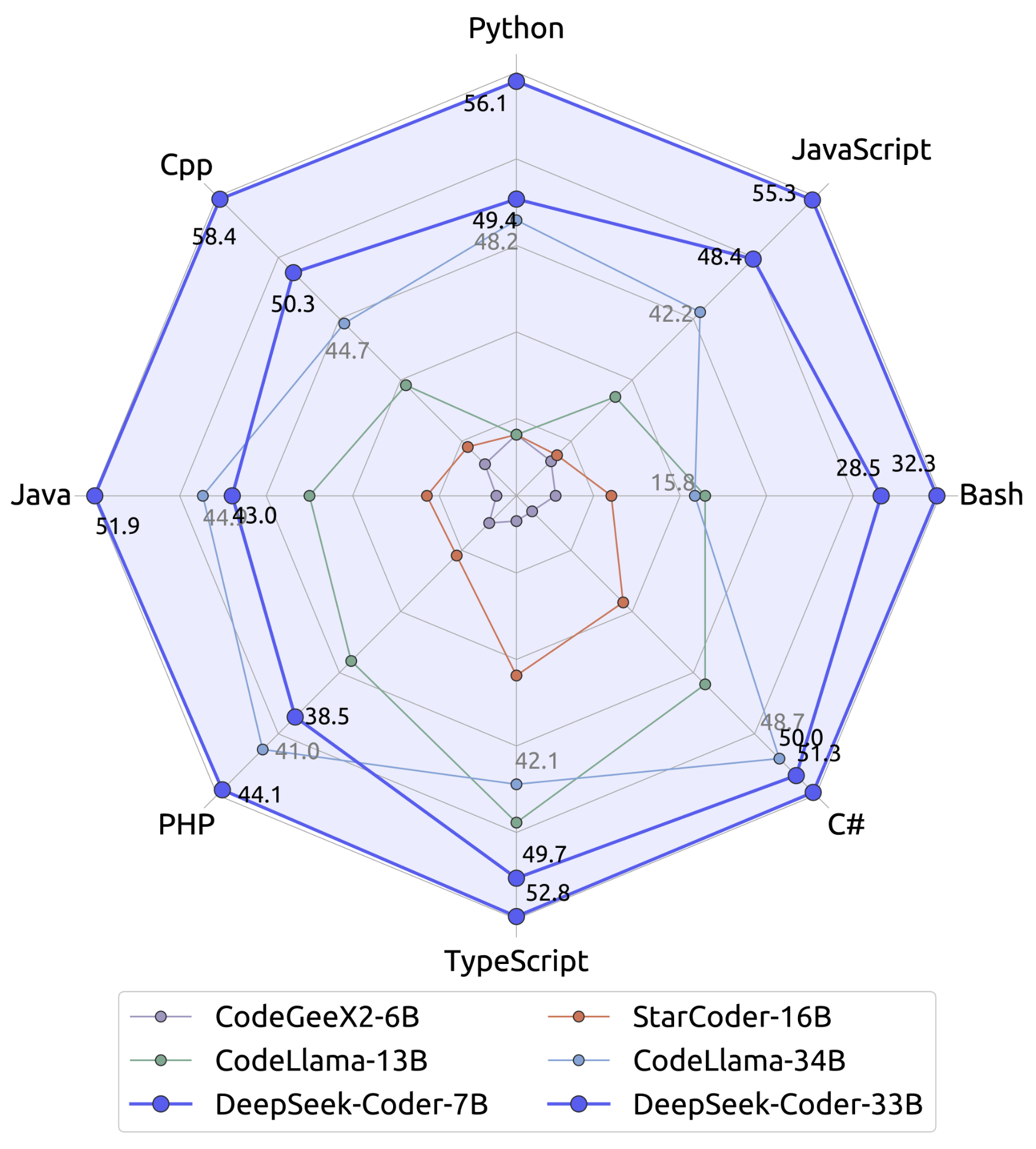 But then they pivoted to tackling challenges as a substitute of simply beating benchmarks. This implies they successfully overcame the previous challenges in computational efficiency! Their revolutionary approaches to consideration mechanisms and the Mixture-of-Experts (MoE) method have led to impressive effectivity features. DeepSeek-V2 is a state-of-the-art language model that uses a Transformer architecture combined with an modern MoE system and a specialized consideration mechanism known as Multi-Head Latent Attention (MLA). While much attention within the AI group has been targeted on fashions like LLaMA and Mistral, DeepSeek has emerged as a significant player that deserves closer examination. We open-source distilled 1.5B, 7B, 8B, 14B, 32B, and 70B checkpoints based mostly on Qwen2.5 and Llama3 sequence to the group. This approach set the stage for a series of rapid model releases. DeepSeek Coder supplies the power to submit current code with a placeholder, in order that the model can full in context. We reveal that the reasoning patterns of larger fashions might be distilled into smaller fashions, resulting in better performance compared to the reasoning patterns discovered by RL on small fashions. This normally involves storing a lot of information, Key-Value cache or or KV cache, quickly, which might be gradual and memory-intensive. Good one, it helped me so much.
But then they pivoted to tackling challenges as a substitute of simply beating benchmarks. This implies they successfully overcame the previous challenges in computational efficiency! Their revolutionary approaches to consideration mechanisms and the Mixture-of-Experts (MoE) method have led to impressive effectivity features. DeepSeek-V2 is a state-of-the-art language model that uses a Transformer architecture combined with an modern MoE system and a specialized consideration mechanism known as Multi-Head Latent Attention (MLA). While much attention within the AI group has been targeted on fashions like LLaMA and Mistral, DeepSeek has emerged as a significant player that deserves closer examination. We open-source distilled 1.5B, 7B, 8B, 14B, 32B, and 70B checkpoints based mostly on Qwen2.5 and Llama3 sequence to the group. This approach set the stage for a series of rapid model releases. DeepSeek Coder supplies the power to submit current code with a placeholder, in order that the model can full in context. We reveal that the reasoning patterns of larger fashions might be distilled into smaller fashions, resulting in better performance compared to the reasoning patterns discovered by RL on small fashions. This normally involves storing a lot of information, Key-Value cache or or KV cache, quickly, which might be gradual and memory-intensive. Good one, it helped me so much.
A promising direction is the usage of massive language models (LLM), which have proven to have good reasoning capabilities when skilled on massive corpora of text and math. AI Models being able to generate code unlocks all kinds of use circumstances. Free for business use and totally open-source. Fine-grained expert segmentation: DeepSeekMoE breaks down every skilled into smaller, extra focused elements. Shared skilled isolation: Shared experts are particular experts which are at all times activated, regardless of what the router decides. The model checkpoints are available at this https URL. You're able to run the mannequin. The excitement round DeepSeek-R1 is not only because of its capabilities but also as a result of it is open-sourced, permitting anyone to obtain and run it domestically. We introduce our pipeline to develop DeepSeek-R1. This is exemplified in their DeepSeek-V2 and DeepSeek-Coder-V2 models, with the latter extensively considered one of the strongest open-supply code models accessible. Now to another DeepSeek giant, DeepSeek-Coder-V2!
The deepseek, Visit Web Page, Coder ↗ fashions @hf/thebloke/deepseek-coder-6.7b-base-awq and @hf/thebloke/deepseek-coder-6.7b-instruct-awq at the moment are obtainable on Workers AI. Account ID) and a Workers AI enabled API Token ↗. Developed by a Chinese AI company DeepSeek, this mannequin is being compared to OpenAI's top models. These models have proven to be far more environment friendly than brute-drive or pure rules-primarily based approaches. "Lean’s comprehensive Mathlib library covers numerous areas similar to analysis, algebra, geometry, topology, combinatorics, and likelihood statistics, enabling us to attain breakthroughs in a more common paradigm," Xin said. "Through several iterations, the mannequin skilled on giant-scale synthetic knowledge becomes considerably more powerful than the initially underneath-trained LLMs, resulting in larger-high quality theorem-proof pairs," the researchers write. The researchers evaluated their mannequin on the Lean four miniF2F and FIMO benchmarks, which comprise lots of of mathematical problems. These methods improved its efficiency on mathematical benchmarks, attaining move rates of 63.5% on the high-college degree miniF2F test and 25.3% on the undergraduate-level ProofNet take a look at, setting new state-of-the-art outcomes. DeepSeek-R1-Distill-Qwen-32B outperforms OpenAI-o1-mini throughout various benchmarks, reaching new state-of-the-artwork outcomes for dense models. The ultimate five bolded models have been all introduced in about a 24-hour period simply earlier than the Easter weekend. It's attention-grabbing to see that 100% of those companies used OpenAI models (most likely through Microsoft Azure OpenAI or Microsoft Copilot, somewhat than ChatGPT Enterprise).
댓글목록
등록된 댓글이 없습니다.