Deepseek Ai Once, Deepseek Ai Twice: Three The explanation why You Sho…
페이지 정보
작성자 Karolin 작성일25-02-04 22:55 조회3회 댓글0건관련링크
본문
Proliferation by default. There's an implicit assumption in many AI security/governance proposals that AGI development will likely be naturally constrained to only a few actors because of compute requirements. Highly Flexible & Scalable: Offered in model sizes of 1B, 5.7B, 6.7B and 33B, enabling users to decide on the setup best suited for their necessities. The DeepSeek site-Coder-Instruct-33B model after instruction tuning outperforms GPT35-turbo on HumanEval and achieves comparable results with GPT35-turbo on MBPP. Particularly noteworthy is the achievement of DeepSeek Chat, which obtained a powerful 73.78% pass fee on the HumanEval coding benchmark, surpassing models of similar measurement. It’s non-trivial to grasp all these required capabilities even for people, let alone language models. This approach combines natural language reasoning with program-based mostly problem-fixing. The Artificial Intelligence Mathematical Olympiad (AIMO) Prize, initiated by XTX Markets, is a pioneering competition designed to revolutionize AI’s role in mathematical problem-fixing. Major US tech stocks - including Nvidia, Microsoft and Tesla - suffered a gorgeous $1 trillion rout on Monday as fears over an advanced Chinese synthetic intelligence mannequin triggered hysteria from Wall Street to Silicon Valley. Reducing the complete record of over 180 LLMs to a manageable measurement was completed by sorting based on scores after which costs.
One of many standout features of DeepSeek’s LLMs is the 67B Base version’s distinctive efficiency in comparison with the Llama2 70B Base, showcasing superior capabilities in reasoning, coding, arithmetic, and Chinese comprehension. It’s straightforward to see the combination of techniques that lead to giant performance positive aspects compared with naive baselines. Below we current our ablation examine on the techniques we employed for the coverage model. It requires the mannequin to understand geometric objects primarily based on textual descriptions and carry out symbolic computations using the gap formula and Vieta’s formulation. Pretraining requires too much of data and computing energy. LLM lifecycle, protecting topics reminiscent of data preparation, pre-training, fine-tuning, instruction-tuning, desire alignment, and sensible functions. Chinese AI startup DeepSeek AI has ushered in a brand new period in giant language models (LLMs) by debuting the DeepSeek LLM family. Furthermore, DeepSeek released their models below the permissive MIT license, which allows others to make use of the models for personal, tutorial or business purposes with minimal restrictions. DeepSeek AI’s resolution to open-source both the 7 billion and 67 billion parameter variations of its fashions, including base and specialized chat variants, aims to foster widespread AI analysis and business applications.
DeepMind - a Google subsidiary targeted on AI analysis - has round seven-hundred whole employees and annual expenditures of over $400 million.27 Salaries of Chinese AI PhD’s educated in China are generally much decrease than salaries of Western AI PhD’s, or Western-educated Chinese, which makes estimating the AIRC’s finances based mostly on workers troublesome. In response to Clem Delangue, the CEO of Hugging Face, one of many platforms hosting DeepSeek’s fashions, builders on Hugging Face have created over 500 "derivative" models of R1 which have racked up 2.5 million downloads combined. Amazon already gives over 200 books (and climbing) with ChatGPT listed as an author or co-writer. Books for professionals about how to make use of ChatGPT, written by ChatGPT, are additionally on the rise. As DeepSeek has change into extra prominent in the AI discipline, many shoppers are also making an attempt out DeepSeek's AI. More evaluation details could be found within the Detailed Evaluation. To harness the benefits of each methods, we implemented this system-Aided Language Models (PAL) or extra exactly Tool-Augmented Reasoning (ToRA) strategy, initially proposed by CMU & Microsoft.
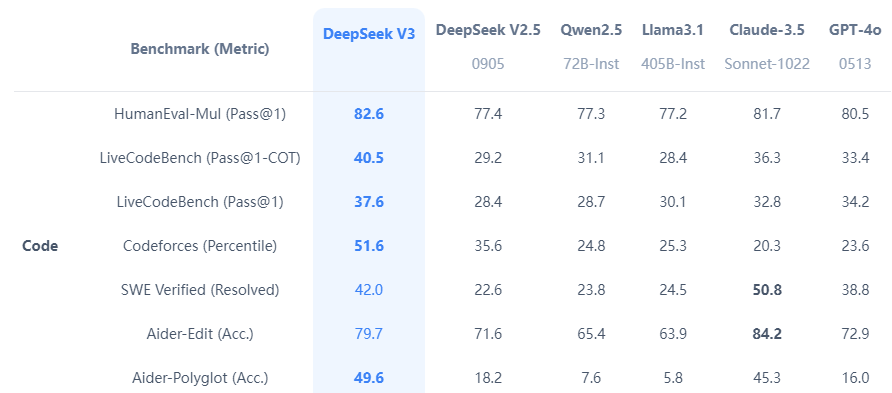 Why this issues - these LLMs actually could be miniature individuals: Results like this show that the complexity of contemporary language fashions is ample to encompass and symbolize a number of the methods by which people respond to basic stimuli. Natural language excels in summary reasoning but falls quick in precise computation, symbolic manipulation, and algorithmic processing. The Jetson Nano line has been a low-value approach for hobbyists and makers to power AI and robotics tasks since its introduction in 2019. Nvidia says the Nano Super’s neural processing is 70 % greater, at 67 TOPS, than the 40 TOPS Nano. While I struggled through the artwork of swaddling a crying child (a fantastic benchmark for humanoid robots, by the way), AI twitter was lit with discussions about DeepSeek-V3. Each of the three-digits numbers to is colored blue or yellow in such a method that the sum of any two (not necessarily different) yellow numbers is equal to a blue number. Each line is a json-serialized string with two required fields instruction and output. She is a extremely enthusiastic particular person with a eager interest in Machine studying, Data science and AI and an avid reader of the most recent developments in these fields.
Why this issues - these LLMs actually could be miniature individuals: Results like this show that the complexity of contemporary language fashions is ample to encompass and symbolize a number of the methods by which people respond to basic stimuli. Natural language excels in summary reasoning but falls quick in precise computation, symbolic manipulation, and algorithmic processing. The Jetson Nano line has been a low-value approach for hobbyists and makers to power AI and robotics tasks since its introduction in 2019. Nvidia says the Nano Super’s neural processing is 70 % greater, at 67 TOPS, than the 40 TOPS Nano. While I struggled through the artwork of swaddling a crying child (a fantastic benchmark for humanoid robots, by the way), AI twitter was lit with discussions about DeepSeek-V3. Each of the three-digits numbers to is colored blue or yellow in such a method that the sum of any two (not necessarily different) yellow numbers is equal to a blue number. Each line is a json-serialized string with two required fields instruction and output. She is a extremely enthusiastic particular person with a eager interest in Machine studying, Data science and AI and an avid reader of the most recent developments in these fields.
댓글목록
등록된 댓글이 없습니다.